

SUBSCRIBE TO OUR NEWSLETTER
Stay informed! Sign up to get expert advice and insight delivered direct to your inbox
When troubleshooting application performance issues, ping alone may not detect the problem. That’s where active testing can help.
September 10, 2018

I’m sure we have all received that call, “VOIP is choppy or application XXX is slow”.
This simple statement sends the support desk down its typical investigative path of test scripts, procedures, and reporting protocols. This common approach often fails to detect the source of the problem. In many cases, what’s needed is active testing to complement these tried and true methods.
I will use web performance as an example even though any application would apply to the following scenario. A typical test would include pinging the web server or DNS server to check if the host is down, has packet loss, or experiences abnormal response times. In most cases, I would bet your pings will be just fine. The analyst will then report that all is well with the web server.
So what is ping missing or why is this not be the best way to troubleshoot this issue?
I will use Microsoft ping to explain since it is the most commonly used by Microsoft clients. Here are some tests to use to get to the bottom of an application performance problem.
Payload: The default ping payload is 32 Bytes which you should increase to match your application payload. For example, if your web application uses 1,000 Byte payload, you should use the –l (dash lowercase L) 1000 option with your ping command. For example ping www.thetechfirm.com –l 1000.
Generally speaking, smaller packets are more likely to get through or return quicker response times.

In the example above, the first set of smaller pings all got through with an average time of 8ms while the second set of larger packets had an average time of 13ms with 25 percent packet loss.
I try to use a tool that allows me to perform a ping sweep or use various payload sizes, like hrping (https://www.cfos.de/en/ping/ping.htm).
Staying on the theme of payload, fragmentation should be taken into consideration. For example, by default Ping’s ICMP and UDP allows fragmentation where TCP does not. The hrping option to set the do not fragment bit on is –f. Now your pings will fail instead of being fragmented.
Interval: The default ping interval for Microsoft is once ping per second and it cannot be modified. In contrast, your HTTP application will generate hundreds, if not thousands, of packets per second. Sending one packet per second lowers the probability that you will encounter an issue or skew your measurements. Chances are that one packet every second will get through. Another reason I use hrping is that it allows me to change the ping interval.
Protocols: Ping uses ICMP, where HTTP uses TCP, and DNS is uses UDP. This means different network equipment may block, spoof, or reroute ICMP packets depending on their configuration. There are additional protocols such as Google QUIC over UDP and others that you may not be aware of.
A HTTP, DNS, or SQL server will treat an ICMP ping differently than an actual application command. Cryping (www.cryer.co.uk) has options to use TCP port numbers, HTTP, and other protocols.
Dependency: You might think that going to a website is a simple process. You visualize that all you do is resolve the host name via DNS, then go to that site. This approach doesn’t factor in multi-tiered servers such as SQL, RADIUS, Oracle, or others that may reside on the backend.
An application command will require more resources, and possible drive writes and reads, to complete your request compared to a simple ping request/response.
Protocol Analysis: I am a student of protocol analysis and I have been practicing it for over 20 years, so this one is my personal favorite.
The first challenge with this approach is how you will capture the packets. For example, capturing from your host requires you to understand if you are using IP, TCP, UDP checksum offloading and why you may see packets larger than the Ethernet maximum (1,518 Bytes). Then there is the tap versus span port debate to keep in mind. I don’t think I’m doing a good job selling you on this approach, am I?
After you captured the packets you need time, patience, and protocol knowledge to calculate DNS, HTTP, TCP, and other response times. Things get tricky when you include HTTPS or QUIC since they are encrypted.
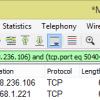
TCP SYN/SYN ACK or connect time is 130 milliseconds
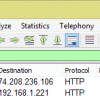
HTTP response time is 170 milliseconds
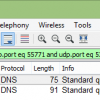
DNS response time is 1 millisecond
Thresholds: Regardless of the technique you use, eventually you will come to this important question. What response time value is good or bad? Unfortunately, there is no cut and dry answer for ‘good’ or ‘bad,’ since it depends on what I call ‘context’. For example, I expect the HTTP response time over a busy WiFi network to an internet website would be different than accessing a local web server with a copper 1 GB connection. A multi-tier application will probably have a different response time than a single tiered application. This is where a baseline comes in. Ideally you should have several previous measurements to compare your results to. Unfortunately, if this process take too much time, you are less likely to do it on a regular interval.
One tip I give regarding determining what is bad and what is a good response time when no baseline is available is to take some sample TCP and application response times as a reference.
Active testing
We have all performed active testing when troubleshooting. Active testing is you actually running the real application on the actual network to the production server. For example, if you get a complaint that webmail is slow, you would launch your browser to see if you encounter the same issues and test accordingly.
Active test systems all have the same architecture consisting of an agent and a console. Every vendor is a bit different so make sure you do your homework to better understand how they work.
In most cases the console controls the agent and gathers/analyzes the results. This is where the vendors start to get unique since some products only support certain operating systems. You should make sure that your solution supports your various operating systems like Microsoft, Apple, Linux, Android, or others.
You should also check if the test scripts are modifiable and if you can create your own. In many cases you might want to test http servers within your network, not just google.com.
Lastly, whatever system you decide to use, it should have built in thresholds and the ability for you to modify them. Ideally you should be able to see the test results, see which threshold caused the test to fail, and adjust accordingly. The idea here is that after a few tests you will develop a baseline of what is normal, good, or bad.
You May Also Like


